AI Engineer Roadmap (2026): From Beginner to Job-Ready
The artificial intelligence landscape continues to mature rapidly. While early iterations focused on conversational interfaces and raw multimodal generation, the industry has shifted toward Compound AI Systems and Agentic Workflows. Enterprises increasingly look beyond standalone models to build autonomous, multi-step systems capable of reasoning, planning, retrieving proprietary data, and securely executing software actions.
For professionals mapping out how to become an AI Engineer, the baseline technical requirements have evolved. The modern AI Engineer learning path focuses less on training foundational models from scratch, a task primarily handled by major research laboratories, and heavily emphasises context engineering, system architecture, and production integration.
This guide provides a structured path through that landscape. Whether you are an experienced software developer, a data professional, or starting fresh, it covers the essential skills, core architectural patterns, and portfolio projects required to transition successfully into an applied AI role.
- What an AI Engineer actually does in 2026 (and how the role has shifted)
- How AI Engineering differs from ML Engineering, Data Science, and research
- The must-learn vs nice-to-learn skills, ranked by production relevance
- A 10-stage sequential learning path from Python fundamentals to deployment
- Three portfolio projects that stand out with hiring managers
- What hiring teams look for, including the red flags that disqualify candidates
1. The Real Role of the AI Engineer
Understanding the AI Engineer career path requires separating long-term engineering realities from cyclical market shifts. Modern AI Engineers function as applied system architects. Their primary responsibility is to bridge the gap between non-deterministic Large Language Models and the highly deterministic infrastructure required by enterprise applications.
The Shift from Prompt Engineering to Context Engineering
In the early stages of generative AI adoption, prompt engineering was frequently highlighted as a core differentiator. Today, basic prompting is considered a foundational skill. The engineering focus has transitioned to Context Engineering, which treats the model as a runtime engine and focuses on building the surrounding infrastructure to deliver precise, secure, and well-structured data.
Effective context engineering requires proficiency in four core areas:
- Retrieval Systems: Engineering pipelines that surface relevant data from multi-format enterprise repositories with low latency.
- Context Window Management: Optimising the density of information sent to a model to maintain reasoning accuracy while controlling token utilisation and API overhead.
- Stateful Memory Systems: Architecting persistent short-term and long-term memory layers that maintain conversation and task state across distributed sessions.
- Tool Execution and Protocols: Equipping systems with external execution capabilities using standards like the Model Context Protocol (MCP) to securely query databases, interact with file systems, or call external REST APIs.
The Rise of Compound AI Systems
Production environments rarely rely on a single model to solve complex business problems. Instead, organisations deploy Compound AI Systems that coordinate multiple specialised components to maximise reliability and maintainability.
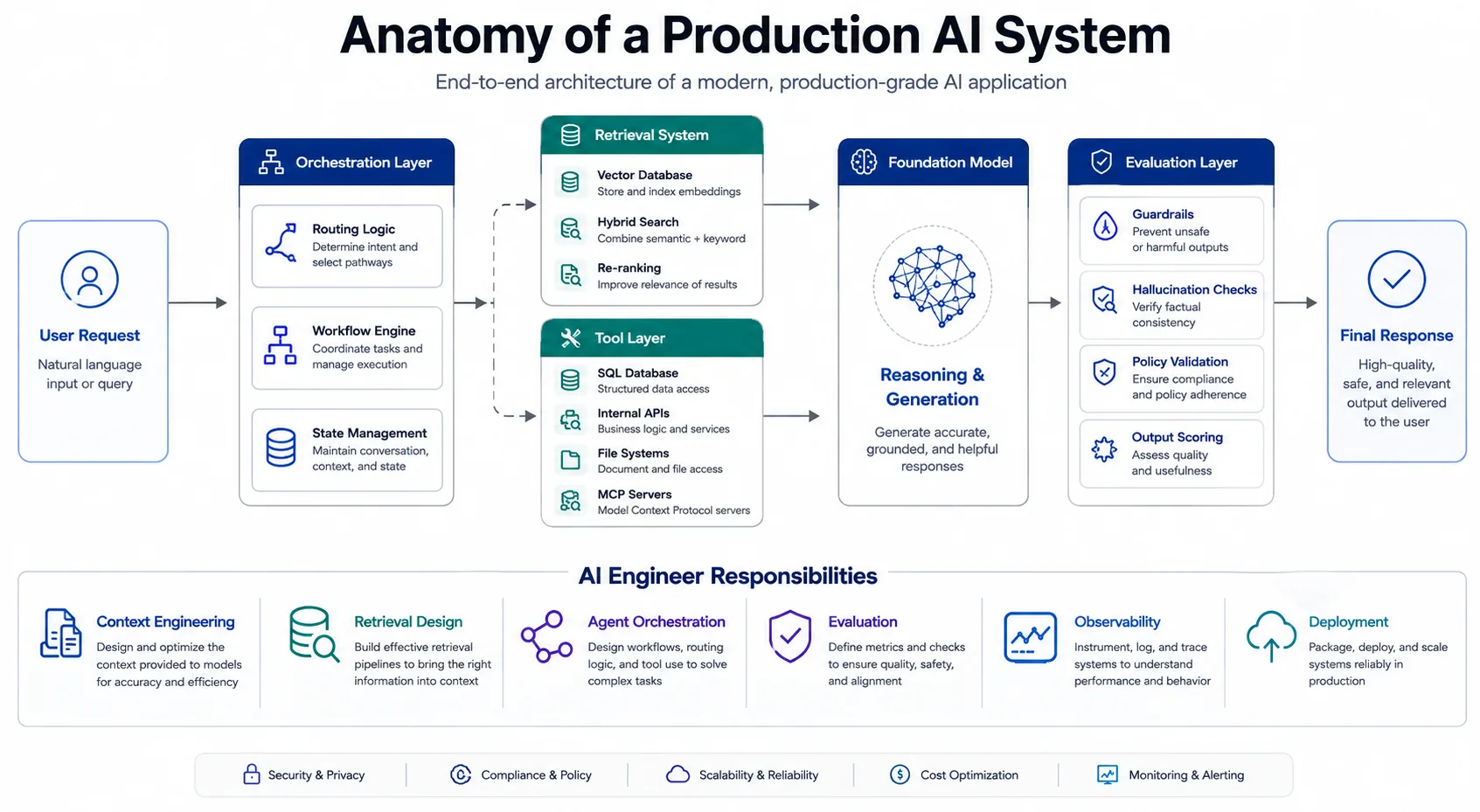
A standard production workflow typically involves multiple discrete steps: a routing engine classifies the user intent, a retrieval pipeline gathers relevant documents from a vector database, an autonomous agent interacts with an internal API tool to fetch live application state, and an evaluation layer validates the output against predefined guardrails before exposing the response.
Production AI is fundamentally an integration and systems engineering challenge, focused on designing robust scaffolding around statistical models.
2. AI Engineering vs Adjacent Roles
Identifying where your existing skills align within the broader technology ecosystem is a critical first step when navigating an AI Engineer career path. The table below outlines how applied AI roles differ from traditional engineering and research disciplines.

| Role | Core Focus | Primary Skills | Hiring Demand |
|---|---|---|---|
| AI Engineer | Building software systems powered by foundation models and agents | Python, LLM APIs, RAG, LangGraph, FastAPI, MCP, LLMOps | High. Strong enterprise demand for application deployment |
| ML Engineer | Training, optimising, and deploying proprietary predictive models | PyTorch, Scikit-learn, CUDA, Kubernetes, MLOps | Stable. Highly critical for specialised, non-generative tasks |
| Data Scientist | Statistical modelling, experimentation, and business insights | SQL, Pandas, R, Statistics, Data Visualisation | Mature. Focus shifting toward data validation and evaluation curation |
| Software Engineer | Developing core application logic, UIs, and backend services | Java, C#, TypeScript, System Design, Databases | Consistent. Teams increasingly require basic AI API literacy |
| AI Researcher | Developing new foundational architectures and training methodologies | Advanced Calculus, Linear Algebra, PyTorch, Deep Learning Theory | Niche. Highly concentrated within foundational AI research labs |
If you have an established background in backend software development, you already possess a substantial portion of the required engineering fundamentals. Your learning curve should focus primarily on handling non-deterministic systems, mastering vector retrieval mechanics, and managing agent state.
AI Engineering focuses on applied software implementation, making it highly accessible to traditional developers who master context management and model integration.
3. Core AI Engineer Skills: Must Learn vs Nice to Learn
Developing a competitive profile requires prioritising skills that ensure application stability and performance over theoretical concepts that are rarely used in production roles.
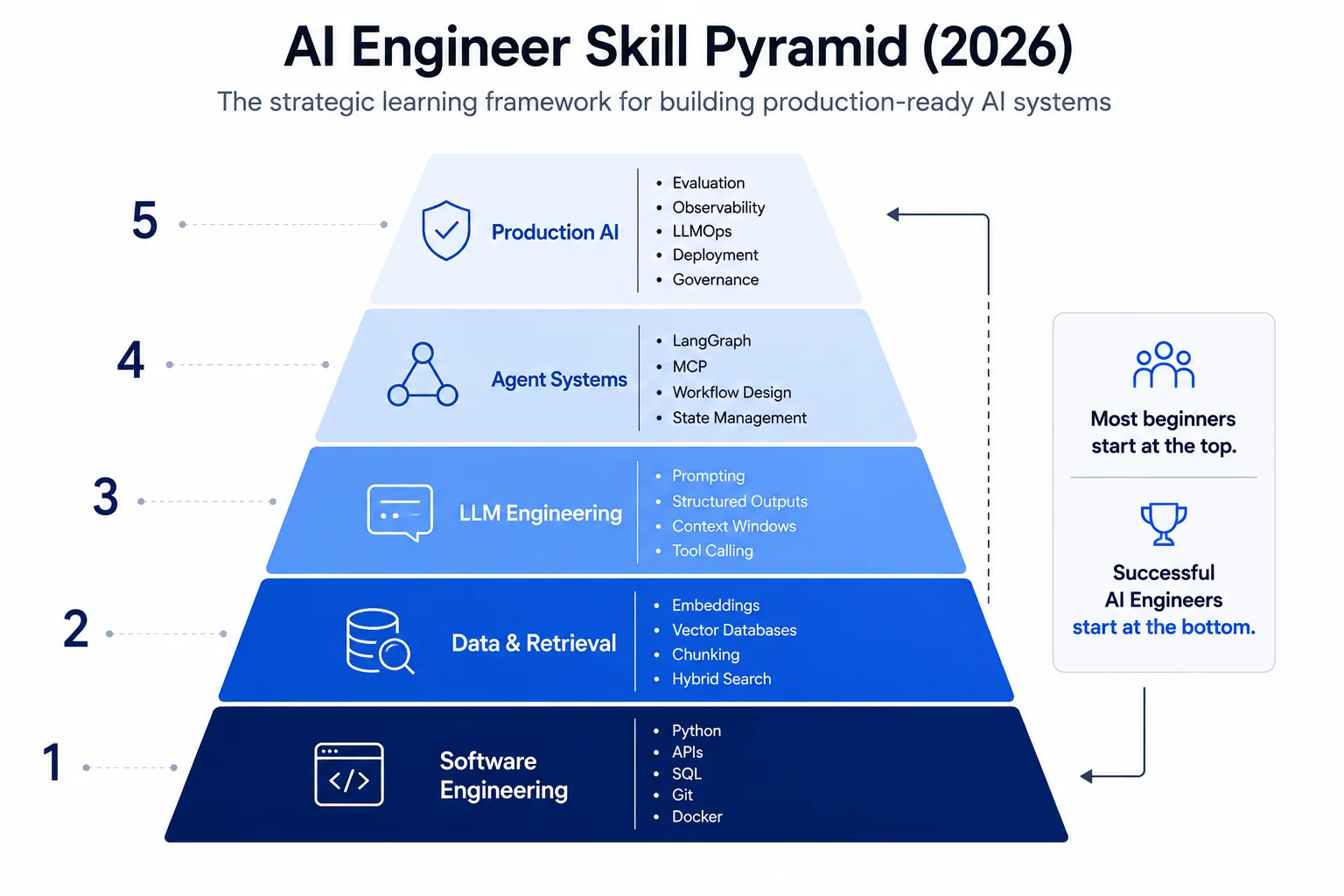
Must Learn: The Core Stack
- Asynchronous Programming: Python remains central to the ecosystem. Because network I/O operations dominate LLM API calls, mastery of asynchronous programming (asyncio) is highly valued in engineering teams.
- Data Validation and Schemas: Using tools like Pydantic is standard practice to enforce strict data structures, parse non-deterministic model outputs, and ensure system boundaries remain reliable.
- Advanced RAG Implementation: Moving beyond simple vector lookups. Production systems frequently require hybrid search, semantic document chunking, and integration of re-ranking models such as Cohere ReRank or BGE Reranker to manage latency and cost trade-offs.
- Agentic Frameworks: LangGraph is widely adopted for deterministic, high-control applications due to its explicit cyclic graph and state-machine design. Frameworks like CrewAI are selected for declarative, role-based multi-agent workflows where rapid configuration is prioritised over strict control.
- The Model Context Protocol (MCP): As an open standard for tool integration, understanding how to construct and integrate MCP servers is increasingly relevant for providing models with access to enterprise data silos.
- Observability and Evaluation: Shifting from manual testing to programmatic validation using tracing tools like LangSmith or Phoenix, and automated evaluation frameworks such as DeepEval, TruLens, or Ragas.
Nice to Learn: Advanced Specialisations
- Model Fine-Tuning: PEFT techniques like LoRA and QLoRA are valuable for specific formatting or stylistic alignment tasks. However, in many enterprise use cases, optimising the RAG pipeline or system prompt delivers higher accuracy with lower compute overhead.
- Low-Level Hardware Optimisation: Writing custom CUDA kernels or managing distributed model parallelisation is highly technical work typically managed by infrastructure-specific engineering teams.
Prioritise reliable data extraction, validation, and systematic evaluation. These skills directly impact enterprise software stability and are what hiring teams assess most rigorously.
4. The 10-Stage Learning Path
A structured, sequential approach ensures you build reliable engineering habits before introducing the complexities of non-deterministic model orchestration. Work through these stages in order.
Progress deliberately from deterministic programming up through complex agentic graphs. Building a strong foundation makes debugging failure modes significantly faster once you encounter non-deterministic model behaviour.
5. Portfolio-Grade AI Engineer Projects
When assessing candidates for applied AI positions, hiring teams prioritise functional, deployed portfolios that demonstrate an understanding of testing, observability, and data validation over generic tutorial replicas.
- Objective: Convert high-volume, variable, unstructured text data into predictable, schema-compliant system data.
- Tech Stack: Python, Pydantic, OpenAI/Anthropic SDKs, PostgreSQL, Docker.
- Key Demonstrations: Graceful API rate-limit management, token efficiency, structural error isolation, and schema enforcement.
- Enterprise Value: Automates expensive data entry tasks cleanly, ensuring downstream relational databases receive strictly validated inputs.
- Objective: A reliable, source-cited document Q&A engine featuring automated regression tracking.
- Tech Stack: FastAPI, Qdrant/Milvus, Cohere ReRank, DeepEval/Ragas, GitHub Actions.
- Key Demonstrations: Context chunk optimisation, hybrid keyword/vector search tuning, and integrated CI/CD evaluation metrics.
- Enterprise Value: Addresses the hallucination challenge systematically, establishing a verifiable baseline for corporate information retrieval.
- Objective: An asynchronous multi-agent coordination application designed to research, analyse, and synthesise reports on target business topics.
- Tech Stack: LangGraph, Tavily Search API, Anthropic Claude, LangSmith Observability.
- Key Demonstrations: State progression handling, custom tool integration, cyclic execution prevention, and deep trace analysis.
- Enterprise Value: Replaces manual research workflows with a highly structured, scalable system that can be monitored for drift and execution cost.
A stand-out portfolio focuses on real-world constraints such as handling malformed data, managing costs, and tracing execution errors. Generic Jupyter notebooks do not demonstrate production readiness.
6. What Hiring Managers Prioritise
Hiring teams look for strong technical software engineering habits applied to the unique challenges of generative models.
Primary Resume Red Flags
- Excessive Theoretical Training with Minimal Code: Accumulating introductory certificates without backing them up with verifiable repositories can indicate a lack of practical debugging experience.
- Absence of Deployed Applications: Code that only runs within a local notebook environment lacks the network, security, and packaging challenges common to production work.
- Overlooking Failure Modes: Asserting that an application using generative models is completely infallible can indicate unfamiliarity with the stochastic nature of these systems.
Positive Technical Signals
- Architectural Clarity: Providing concrete infrastructure schematics that explain the selection of database components, framework abstraction levels, and data flows.
- Focus on Evaluation Metrics: Showing an ability to track system accuracy using objective criteria, such as improving context precision by measurable percentages.
- Adherence to Software Standards: Writing clean, modular repositories that include automated tests, structured exception handling, and clean documentation.
Emphasise your software engineering hygiene, deployment experience, and data validation techniques over pure framework familiarity. Hiring managers hire engineers, not framework users.
7. Future-Proofing Your Career
The frameworks, libraries, and open-source packages prominent today will undergo major iterations over the next decade. Long-term success relies on anchoring your development to foundational engineering disciplines that remain relevant across technology cycles.
- Systems Thinking: Treating the model as one component within a larger distributed network. Understanding how to manage connection pooling, data caching, and asynchronous task queues remains an evergreen technical skill.
- Quality Assurance and Evaluation: As model access becomes commoditised, the core engineering advantage shifts to organisations that can build rigorous evaluation, alignment, and guardrail validation software at scale.
- Data Lifecycle Management: High-quality context data is essential for model performance. Mastering data curation, cleaning pipelines, privacy governance, and enterprise access control represents a resilient engineering skill set.
- Human-In-The-Loop Workflow Design: Architecting intermediate confirmation checkpoints, user feedback capture mechanics, and state rollback systems ensures autonomous agents remain safe and controllable.
FAQ
ML Engineers generally focus on the research, training, tuning, and infrastructure scaling required for custom predictive or classification models. AI Engineers specialise in system integration, building the software architecture, RAG pipelines, and agent frameworks necessary to make pre-trained foundation models stable and production-ready.
You do not need a PhD-level math background. Solid mathematical intuition regarding linear algebra concepts such as matrix multiplication and vector spaces, along with probability statistics, is valuable for understanding embeddings, distance metrics, and evaluation systems.
Not necessarily. Most enterprises prioritise engineering talent that can build reliable data architectures, robust context pipelines, and validated interfaces. Fine-tuning is typically reserved for specialised formatting, structural domain alignment, or local hosting requirements.
Hiring teams prioritise functional, deployed portfolios that demonstrate testing, observability, and data validation. A production RAG system with automated evaluation metrics, a multi-agent LangGraph workflow with trace analysis, and a containerised data extraction pipeline with schema enforcement are the three strongest project types.
Context engineering treats the language model as a runtime engine and focuses on building the surrounding infrastructure to deliver precise, secure, and well-structured data. It covers retrieval systems, context window management, stateful memory, and tool execution protocols. It has replaced basic prompt engineering as the core differentiator for production AI roles.
A Compound AI System coordinates multiple specialised components rather than relying on a single model. A typical production workflow involves a routing engine, a RAG retrieval pipeline, an agent with tool access, and an evaluation layer that validates outputs before returning them to the user. Building and maintaining these systems is the primary job of an AI Engineer.
LangGraph is a framework for building deterministic, high-control agentic applications using an explicit cyclic graph and state-machine design. It is the preferred choice when you need strict execution control, reliable state management, and the ability to handle exception paths in model-driven loops. It is widely adopted in enterprise AI engineering teams.
The 10-stage learning path in this guide can be completed in 4 to 8 months with consistent daily practice, assuming a background in software development. Stages 1 through 5 cover foundational skills and can be completed in 6 to 8 weeks each. Stages 6 through 10 involve building real systems and typically take longer as each stage produces a portfolio-quality project.
MCP is an open standard for tool integration that provides models with structured access to enterprise data silos such as relational databases, file systems, and external REST APIs. Understanding how to construct and integrate MCP servers is increasingly relevant for AI Engineers building production agentic systems.
Hiring managers prioritise software engineering hygiene, deployed applications, and evidence of evaluation-driven development. Positive signals include concrete infrastructure schematics, measurable accuracy improvements, and clean modular repositories with automated tests. Red flags include certificates without verifiable code, notebook-only projects, and claims that generative AI applications are infallible.
Related Role Guides
Interview Prep
Related Concepts to Study
Master AI/ML with AI Prep app
AI Prep covers AI Agents, Generative AI, ML Fundamentals, NLP & LLMs and a lot more, with adaptive tests and daily challenges. Fully offline on Android. Free to try, one-time unlock for lifetime access.